Gestió de la Memòria (Part II)
Unitat 6 · Sistemes Operatius (SO)
Què és la memòria virtual?
La memòria virtual és un mecanisme que permet que els programes s’executin com si disposessin d’un espai d’adreces molt més gran que la Memòria Principal real.
Funciona com un sistema de cache:
- La Memòria Principal (MP) actua com un cache, però a diferència d’un cache no hi ha associativitat ni línies múltiples: la traducció és estrictament per pàgina.
- La Memòria Secundària (MS) (disc/SSD) és la memòria gran però lenta.
- El SO només manté en MP les pàgines que s’estan utilitzant.
L’objectiu és mantenir a la MP el conjunt de treball del procés (les pàgines usades recentment). Quan el conjunt resident ≈ conjunt de treball → el rendiment és òptim.
La MP és la cache de la MS. Les pàgines són els blocs. Les fallades de pàgina són misses de cache.
Característiques de la memòria virtual
Incrementa la multiprogramació: cap procés necessita estar completament a la MP (només les pàgines actives).
Permet executar programes més grans que la MP: només es carreguen pàgines quan cal.
Comportament no determinista del temps d’accés: una instrucció pot trigar nanosegons o mil·lisegons segons si es produeix una fallada de pàgina.
Localitat = rendiment: si el procés segueix un patró de localitat (temporal + espacial), les fallades disminueixen.
Hiperpaginació: si cap procés pot mantenir resident el seu conjunt de treball, el sistema entra en un bucle de fallades → rendiment ≈ 0.
Hiperpaginació = la CPU està ocupada gestionant fallades, no executant programes.
Paginació sota demanda
Les pàgines només es carreguen quan s’hi accedeix per primera vegada.
L’inici del procés és lazy: cap pàgina és resident fins que es referència.
Quan es produeix una fallada:
La MMU genera un trap cap al SO
El SO decideix on col·locar la pàgina
La pàgina es transfereix des del disc
L’execució es reprèn
Aquest enfocament és extremadament eficient quan hi ha localitat.
Paginació anticipada
La idea és reduir el nombre futur de fallades aprofitant la localitat:
- Es carreguen pàgines properes a la que ha fallat (per exemple, seqüencials).
- Pot ser molt útil en lectures seqüencials o recorreguts de codis/arrays.
- Però si la predicció és dolenta → es carrega memòria innecessària i empitjora el rendiment.
Prepaging = precache:
- Funciona quan hi ha patrons previsibles.
- Fracassa quan hi ha accés dispers o saltos aleatoris.
Tractament de la Fallada de Pàgina
Quan la MMU detecta que una pàgina no és resident (F):
- Comprovar si hi ha un marc lliure (MP).
- Si n’hi ha, s’hi carrega la pàgina F.
- Si no hi ha marcs lliures:
- Seleccionar una víctima (V) segons l’algorisme de reemplaçament.
- Invalidar l’entrada de V a la taula de pàgines.
- Si V és dirty, escriure-la al disc.
- Carregar la pàgina F al marc de V.
- Marcar F com a vàlida.
Com que carregar una pàgina pot trigar mil·lisegons, el SO despatxa un altre procés per no bloquejar la CPU.
Què és un TLB?
La TLB (Translation Lookaside Buffer) és una petita memòria associativa que guarda les traduccions recents d’adreces virtuals → físiques.
- El seu objectiu és accelerar l’accés a memòria.
- Actua com una cache de la taula de pàgines.
- Si la TLB té l’entrada que busquem → trobem ràpidament el marc físic.
- Això evita consultes lentes a la taula de pàgines (que sol estar a memòria).
TLB = cache de traduccions. Si hi ha encert (hit), no cal consultar la taula de pàgines.
TLB Hit vs. TLB Miss
Quan la CPU genera una adreça virtual:
- TLB Hit
- La TLB conté la traducció.
- L’accés a memòria és ràpid (només un accés real a DRAM).
- TLB Miss
- La TLB no conté la traducció.
- La MMU consulta la taula de pàgines a la MP.
- Després actualitza la TLB amb la nova entrada.
- Si la PTE (Page Table Entry) indica que la pàgina no està a MP → es produeix fallada de pàgina.
Per què necessitem una TLB?
Consultar la taula de pàgines és lent perquè:
- Normalment implica 1 o 2 accessos a memòria (multinivell).
- A cada accés s’ha de fer la traducció del marc físic de la PTE.
- Si féssim 2 accessos per cada lectura de memòria → el sistema seria massa lent.
La TLB permet:
- Reduir la latència de traducció.
- Executar programes com si la traducció fos gratis.
- Aprofitar la localitat temporal: s’accedeix repetidament a les mateixes pàgines.
Traduir cada adreça no pot ser més lent que accedir a memòria.
Accés en paral·lel
Els processadors moderns fan l’accés a TLB i cache en paral·lel, perquè:
- La part desplaçament de l’adreça virtual és la mateixa en l’adreça física. Permet calcular l’índex de la cache abans de tenir la traducció completa.
- La CPU envia l’adreça virtual.
- La TLB busca la traducció mentre la cache comença a buscar per l’índex.
- Si la TLB fa hit, s’omple la resta de l’adreça física i s’acaba la cerca.
- Accés molt ràpid, sense esperes addicionals.
TLB + Cache treballen en paral·lel per reduir el temps d’accés efectiu.
TEA: Temps Efectiu d’Accés (sense fallades)
El Temps Efectiu d’Accés (TEA) és el temps mig per accedir a memòria tenint en compte:
Si la TLB fa hit (accés ràpid)= \(\text{TEA hit}=t_{TLB}+t_{MP}\)
Si la TLB fa miss (cal consultar la taula de pàgines a la MP)= \(\text{TEA miss}=t_{TLB}+2\cdot t_{MP}\)
\[TEA = (p \cdot \text{TEA hit}) + ((1-p) \cdot \text{TEA miss})\]
On: \(t_{TLB}\) = temps d’accés a la TLB, \(t_{MP}\) = temps d’accés a la Memòria Principal, \(p\) = taxa d’encerts de la TLB (TLB hit rate).
Com més alta és la taxa d’encerts de la TLB, més ràpid és l’accés efectiu.
Temps MS->MP
Els discs són el dispositiu de paginació tradicional més utilitzat. Comparats amb la Memòria Principal, els discs (sobretot els HDD) són moltes orders de magnitud més lents. Quan es carrega una pàgina de la Memòria Secundària (MS) a la Memòria Principal (MP), el temps total ve determinat per:
- Temps de cerca \(T_{c}\): Temps necessari perquè les capçals mecàniques es col·loquin sobre el cilindre correcte.
- Temps de latència \(T_{l}\): Temps d’espera fins que el sector de la pàgina passa sota la capçal (rotació del disc).
- Temps de transferència \(T_{t}\): Temps necessari per llegir la pàgina completa i enviar-la cap a la MP.
\[T_{MS-MP} = T_{c} + T_{l} + T_{t}\]
Ordres de magnitud
- Temps de cerca \(T_{c}\): Depèn del disseny físic del disc i de l’algorisme d’assignació de sectors. Sol ser de l’ordre dels mil·lisegons (ms).
- Temps de latència \(T_{l}\): Depèn de la velocitat de rotació del disc. Sol ser de l’ordre dels mil·lisegons (ms).
- Temps de transferència \(T_{t}\): Depèn de l’amplada de banda del disc i de la mida de la pàgina. Sol ser de l’ordre dels mil·lisegons (ms).
Un SSD/NVMe redueix significativament aquests temps (ordre \(\mu s\), no té \(T_{c}\) ni \(T_{l}\)), però encara és molt més lent que la MP.
Una fallada de pàgina pot ser 100.000×-1000× més lenta que un accés normal! Encara que \(P\) sigui molt petit, el cost d’una fallada de pàgina és tan elevat que pot disparar dramàticament el TEA.
TEA amb fallades
\[TEA = [ (1-p) \cdot (T_{a})] + [p \cdot (T_{fp})]\]
on:
- \(p\) = probabilitat de fallada de pàgina.
- \(T_{a}\) = temps d’accés quan no hi ha fallada de pàgina (TLB hit/miss + MP).
- \(T_{fp}\) = temps d’accés quan hi ha fallada de pàgina.
- \(MS-MP\) = temps per portar la pàgina des de MS a MP.
- temps de reemplaçament (si hi ha víctima)
- temps d’actualitzar la taula de pagines.
- temps de rependrè la execució.
Ex01: TEA amb Paginació
- Disposem d’un disc que gira a \(7.500 rev/min\).
- Aquest disc té un temps de cerca de \(2ms\) i transfereix \(100.000\) paraules/s.
- La probabilitat de fallada és de \(P=0,25\)
- La mida d’una pàgina és \(1.000\) paraules.
- Els sistema de gestió de memòria és Paginació (la taula de pàgines s’implementa en MP)
- El Temps d’accés (\(T_{a}\)) a MP és \(4 \mu s\).
- Assumeix per simplicitat que no fem servir TLB.
- Calcular \(TEA\).
Ex01: TEA amb Paginació(I)
\[T_{a} = 4 \mu s = 4 \cdot 10^{-6} s\]
\[ T_{c} = 2ms = 2 \cdot 10^{-3}s\]
\[T_{l} = 7500 \frac{rev}{min} \cdot \frac{1 min}{60 seg} = 125 \frac{rev}{seg} \rightarrow T_{l} = \frac{1}{2} \cdot \frac{1}{125}s = 4 \cdot 10^{-3} s\]
\[T_{t} = 100.000 \frac{paraules}{segon} \cdot \frac{1 pagina}{1.000 paraules} = 100 \frac{pagines}{segon} \rightarrow T_{t} = 10^{-2} s = 10 \cdot 10^{-3} s\]
\[T_{MP-MS} = T_{c} + T_{l} + T_{t} = 2 \cdot 10^{-3} + 4 \cdot 10^{-3} + 10 \cdot 10^{-3} = 16 \cdot 10^{-3}s\]
La relació \(\frac{1}{2}\) és un assumpció comuna en el context dels discos durs. Fa referencia al temps mitjà que tarda el disc a girar per situar-se a la pista/cilindre desitjat per fer una operació de lectura o escriptura.
Ex01: TEA amb Paginació(II)
\[TEA = [(1-P) \cdot (T_{a})] + [P \cdot (T_{fp})]\]
Com el sistema de gestió de memòria és Paginació:
Si no hi ha fallada de pàgina, el temps d’accés a Memòria Principal és \(2 \cdot T_{a}\). Ja que s’ha d’accedir a la taula de pàgines i a la pàgina.
En cas de fallada de pàgina, el temps d’accés a Memòria Principal és \(T_{MP-MS} + 3 \cdot T_{a}\). Ja que s’ha d’accedir a la taula de pàgines, després s’ha de carregar la pàgina a Memòria Principal, accedir a la pàgina i finalment accedir a la taula de pàgines per marcar la pàgina com a vàlida (actualització de la taula).
\[TEA = [(1-P) \cdot (2 \cdot T_{a})] + [P \cdot (T_{MP-MS} + 3 \cdot T_{a})]\] \[TEA = [(1-0,25) \cdot (2 \cdot 4 \cdot 10^{-6})] + [0,25 \cdot (16 \cdot 10^{-3} + 3 \cdot 4 \cdot 10^{-6})]\] \[TEA = 4,009 \; ms\]
Ex02: TEA & Segmentació Paginada
Suposeu que tenim un sistema amb memòria virtual (del tipus paginació sota demanda). El sistema de gestió de memòria és Segmentació Paginada. Totes les taules (de segments i de pàgines) s’implementen en M.P (Memòria Principal). Les pàgines tenen 1.000 paraules. El dispositiu de paginació és un disc dur amb un temps de cerca mig de \(10 ms\). El disc dur gira a 7.200 revolucions per minut i transfereix 1.000.000 paraules per segon. Assumeix que el TLB no s’utilitza.
D’entre tots els accessos, el 20% dels mateixos es realitzen a pàgines carregades en M.P. Quan es produeix una fallada de pàgina, el 60% de les vegades es reemplaça una pàgina. El 70% de les vegades, la pàgina a reemplaçar ha estat accedida solament en mode lectura. Quan es produeix una fallada de pàgina, l’actualització de les taules de pàgines dels processos triga \(1 \mu s\). El temps d’accés a memòria és \(2 \mu s\).
Quin és el temps efectius d’accés (TEA) a M.P.?
Ex02: TEA & Seg.Pag (I)
Calculem els diferents temps:
- \(T_c = 10 ms = 10 \cdot 10^{-3} s\)
- \(T_l = 7200 \frac{rev}{min} \cdot \frac{1 min}{60 seg} = 120 \frac{rev}{seg} \rightarrow T_l = \frac{1}{2} \cdot \frac{1}{120} s = 4,166 \cdot 10^{-3} s \approx 4 \cdot 10^{-3} s\)
- \(T_t = 1.000.000 \frac{paraules}{segon} \cdot \frac{1 pagina}{1.000 paraules} = 1.000 \frac{pagines}{segon} \rightarrow T_t = 10^{-3} s\)
- \(T_{MP-MS} = T_c + T_l + T_t = 10 \cdot 10^{-3} + 4 \cdot 10^{-3} + 10^{-3} = 15 \cdot 10^{-3} s\)
- \(T_a = 2 \mu s = 2 \cdot 10^{-6} s = 0,002 \cdot 10^{-3} s\)
- \(T_{Ac-Tau} = 1 \mu s = 1 \cdot 10^{-6} s = 0,001 \cdot 10^{-3} s\)
Ex02: TEA & Seg.Pag (II)
- 20% de les vegades: (no hi ha fallada de pàgina).
- 80% de les vegades: (hi ha fallada de pàgina).
- 60% de les vegades: (hi ha fallada de pàgina i es reemplaça una pàgina). 30% de les vegades (Cel·la vícitma modificada) i el 70% de les vegades: (Cel·la víctima no modificada)
- 40% de les vegades: (hi ha fallada de pàgina i no es reemplaça una pàgina).
\[\begin{equation*} \begin{split} TEA = & \, 0.2 \cdot (\text{Temps NO fallada}) + 0.8 \cdot (\text{Temps fallada}) \\ = & \, 0.2 \cdot (\text{Temps NO fallada}) \\ & + 0.8 \cdot \left[ 0.6 \cdot (\text{Temps reemplaçament}) + 0.4 \cdot (\text{Temps sense reemplaçament}) \right] \end{split} \end{equation*}\]
\[\begin{align*} \text{Temps reemplaçament} &= (0.3 \cdot \text{Temps intercanvi cel·la/pàgina (MP - MS)}) \\ &+ (0.7 \cdot \text{Temps moure pàgina (MS a MP)}) \\ \end{align*}\]
Ex02: TEA & Seg.Pag (III)
\[ \text{Temps NO fallada} = 3 \cdot T_a \]
- 1 accés a la taula de segments.
- 1 accés a la taula de pàgines.
- 1 accés a la cel·la.
\[ TEA = \frac{20}{100} \cdot (3 \cdot T_a) + \frac{80}{100} \cdot \text{Temps fallada} \]
Ex02: TEA & Seg.Pag (IV)
\[ \text{Temps fallada} = \frac{60}{100} \cdot \text{Temps reemplaçament} + \frac{40}{100} \cdot \text{Temps sense reemplaçament} \]
On: \(\text{Temps sense reemplaçament} = T_{MP-MS} + 5 \cdot T_a + T_{Ac-Tau}\)
- 1 accés a la taula de segments.
- 1 accés a la taula de pàgines. -> Pàgina no a MP
- 1 accés a la taula de segments.
- 1 accés a la taula de pàgines.
- 1 accés a la cel·la.
- Portar la pàgina de MS a MP.
- Actualitzar les taules.
Ex02: TEA & Seg.Pag (V)
\[\begin{equation*} \begin{split} TEA = &\frac{20}{100} \cdot (3 \cdot T_a) \\ &+ \frac{80}{100} \cdot \left[ \frac{60}{100} \cdot \text{Temps reemplaçament} + \frac{40}{100} \cdot \left( T_{MP-MS} + 5 \cdot T_a + T_{Ac-Tau} \right) \right] \end{split} \end{equation*}\]
Ex02: TEA & Seg.Pag (IV)
\[ \text{Temps reemplaçament} = \frac{30}{100} \cdot \text{Temps Modificada} + \frac{70}{100} \cdot \text{Temps No Modificada} \]
On: \(\text{Temps No Modificada} = T_{MP-MS} + 5 \cdot T_a + T_{Ac-Tau}\)
- 1 accés a la taula de segments.
- 1 accés a la taula de pàgines. -> Pàgina no a MP
- 1 accés a la taula de segments.
- 1 accés a la taula de pàgines.
- 1 accés a la cel·la.
- Portar la pàgina de MS a MP.
- Actualitzar les taules.
Ex02: TEA & Seg.Pag (V)
\[ \text{Temps reemplaçament} = \frac{30}{100} \cdot \text{Temps Modificada} + \frac{70}{100} \cdot \text{Temps No Modificada} \]
On: \(\text{Temps Modificada} = 2 \cdot T_{MP-MS} + 5 \cdot T_a + T_{Ac-Tau}\)
- 1 accés a la taula de segments.
- 1 accés a la taula de pàgines. Pàgina no a MP
- 1 accés a la taula de segments.
- 1 accés a la taula de pàgines.
- 1 accés a la cel·la.
- Guardar a MS la cel·la víctima modificada.
- Portar la pàgina de MS a MP.
- Actualitzar les taules.
Ex02: TEA & Seg.Pag (VI)
\[\begin{equation*} \begin{split} TEA = &\frac{20}{100} \cdot (3 \cdot T_a) \\ &+ \frac{80}{100} \cdot \left[ \begin{aligned} &\frac{40}{100} \cdot \left( T_{MP-MS} + 5 \cdot T_a + T_{Ac-Tau} \right) \\ &+ \frac{60}{100} \cdot \left[ \begin{aligned} &\frac{30}{100} \cdot \left( 2 \cdot T_{MP-MS} + 5 \cdot T_a + T_{Ac-Tau} \right) \\ &+ \frac{70}{100} \cdot \left( T_{MP-MS} + 5 \cdot T_a + T_{Ac-Tau} \right) \end{aligned} \right] \end{aligned} \right] \end{split} \end{equation*}\]
\[TEA = 14,17 \; ms\]
Gestió de marcs
La gestió de marcs (frames) determina què s’assigna a cada procés i què s’expulsa quan cal alliberar espai a la Memòria Principal (MP).
- Algorismes d’assignació: Determinen quines cel·les de la Memòria Principal són assignades a cada procés.
- Assignació Local.
- Assignació Global.
- Algorismes de reemplaçament: Determinen quines cel·les de la Memòria Principal són substituïdes quan es produeix una fallada de pàgina i no hi ha cap cel·la lliure.
- Òptim.
- FIFO.
- Segona Oportunitat.
- LRU.
- Buffering de pàgines.
Assignació local
- Aquest algorisme assigna a cada procés un nombre fix de cel·les (marcs) a la Memòria Principal.
- Davant d’una fallada de pàgina, només es poden substituir pàgines del mateix procés que l’ha provocada.
- Evita que un procés monopolitzin totes les cel·les de la MP, mantenint un cert aïllament entre processos.
- Aquesta tècnica limita l’impacte de la substitució: cap procés pot expulsar pàgines d’un altre, reduint interferències.
Min. nº de cel·les per procés?
Cal garantir que qualsevol instrucció que el procés executi pot ser resolta amb les pàgines que té assignades.
El nombre mínim de cel·les dependrà de:
- El format de la instrucció (quantes paraules ocupa).
- El tipus d’adreçament dels operands:
- Immediat: 0 cel·les extra.
- Directe: 1 cel·la.
- Indirecte: 2 cel·les (perquè cal llegir l’adreça i després accedir-hi).
- Indexat: 1 cel·la addicional.
- L’accés a la cel·la on s’escriu el resultat.
Aquest mínim determina el nombre de marcs que cal assignar al procés perquè pugui executar qualsevol instrucció sense fallades permanents.
Ex03: Assignació local – Càlcul del mínim nombre de cel·les
Suposeu que el format d’una instrucció ocupa dues paraules (mida paraula = 1 Byte):
- Paraula 1 = OPCODE + Paraula 2 = OPERANDS, que conté els codis de mode d’adreçament dels tres operands (OP1, OP2, RES).
- Els valors o adreces referenciades pels operands no formen part de la instrucció, sinó que resideixen a cel·les de memòria independents.
Quin és el mínim nombre de cel·les que cal assignar a un procés? Suposem que OP1 i OP2 són operands d’adreçament indirecte i RES és directe.
- OP1 (indirecte): cal llegir 2 cel·les
- OP2 (indirecte): cal llegir 2 cel·les
- RES (directe): cal una 1 cel·la
- Total mínim = 2 (instrucció) + 2 + 2 + 1 = 7 cel·les de MP
Assignació global
En l’assignació global, els marcs de la Memòria Principal (MP) es distribueixen entre tots els processos considerant la visió global del sistema. A diferència de l’assignació local, en aquest model:
- El sistema pot redistribuir marcs dinàmicament entre processos
- Un procés pot expulsar pàgines d’altres processos. Això només passa quan el sistema utilitza reemplaçament global. Pots tenir assignació global + reemplaçament local o viceversa.
Hi ha dues estratègies habituals:
- Assignació Igualitària: Cada procés rep un nombre igual de marcs, independentment de les seves necessitats o comportament.
- Assignació Proporcional: Els marcs es distribueixen segons les necessitats o la mida de cada procés, permetent que processos més grans tinguin més marcs.
Ex04: Igualitària vs Proporcional
Suposeu que disposem d’una MP de 8 cel·les. Si tenim 3 processos, amb uns requeriments de memòria de P1 (6 cel·les), P2 (3 cel·les) i P3 (2 cel·les). Quina serà l’assignació de Memòria segons els algorismes d’Assignació Igualitària i Proporcional?
Assignació Igualitària: Cada procés té assignades \(\frac{8}{3} = 2,66\) cel·les de MP. Per tant, el procés P1 té assignades 2 cel·les de MP, el procés P2 té assignades 2 cel·les de MP i el procés P3 té assignades 2 cel·les de MP. En total hi ha 2 cel·les lliures.
Assignació Proporcional:
- Procés P1: \(\frac{6 \cdot 8}{6+3+2} = 4,36\) cel·les de MP (4 cel·les de MP).
- Procés P2: \(\frac{3 \cdot 8}{6+3+2} = 2,18\) cel·les de MP (2 cel·les de MP).
- Procés P3: \(\frac{2 \cdot 8}{6+3+2} = 1,09\) cel·les de MP (1 cel·la de MP).
- En total hi ha 1 cel·la lliure.
Retenció de pàgines
No totes les pàgines residents a Memòria es poden reemplaçar. Hi ha pàgines que no es poden reemplaçar perquè són necessàries, com per exemple les pàgines que contenen les funcions del sistema operatiu.
A més a més, en sistemes linux, existeix la crida a sistema mlock que permet fixar una pàgina a la Memòria Principal.
Reemplaçament de pàgines - Òptim
L’algorisme Òptim (OPT) substitueix la pàgina que no tornarà a ser necessària durant més temps en el futur.
És la política que minimitza el nombre total de fallades de pàgina, però no es pot implementar en temps real, ja que requereix conèixer l’accés futur. S’utilitza com a referència teòrica (llindar inferior).
Mirar endavant en la seqüència d’accés -> expulsar la pàgina amb la pròxima referència més llunyana (o que no es torna a referenciar).
Regla farthest next use, i si totes són infinits (no es tornen a usar) el resultat depèn de la tria arbitrària —> totes les opcions són igualment òptimes en aquell punt.
Ex: Reemplaç Òptim
Assumeix 3 marcs i la següent seqüència de referències a pàgines: 0 → 7 → 5 → 8 → 10 → 12 → 0 → 10 → 8 → 5 → 9 → 7
Funcionament
| Pas | Referència | Marcs | Page fault? |
|---|---|---|---|
| 0 | 0 | [0, –, –] | Sí (1) |
| 1 | 7 | [0, 7, –] | Sí (2) |
| 2 | 5 | [0, 7, 5] | Sí (3) |
| 3 | 8 | [0, 8, 5] | Sí (4) — reemplaça 7 (proper ús futur a posició 11) |
| 4 | 10 | [0, 8, 10] | Sí (5) — reemplaça 5 (proper ús futur a posició 9) |
| 5 | 12 | [0, 12, 10] | Sí (6) — reemplaça 8 (proper ús futur a posició 8) |
| 6 | 0 | [0, 12, 10] | No (hit) |
| 7 | 10 | [0, 12, 10] | No (hit) |
| 8 | 8 | [0, 8, 10] | Sí (7) — totes les altres pàgines no tornen a aparèixer; escollim una (per exemple 12) |
| 9 | 5 | [5, 8, 10] | Sí (8) — escollim expulsar 0 (no apareix més endavant) |
| 10 | 9 | [9, 8, 10] | Sí (9) — expulsar 5 (no torna a aparèixer) |
| 11 | 7 | [7, 8, 10] | Sí (10) — expulsar 9 |
Reemplaçament de pàgines - FIFO
L’algorisme FIFO és un algorisme de reemplaçament de pàgines que substitueix la pàgina que ha estat a la Memòria Principal durant més temps.
FIFO no utilitza informació del futur. Expulsa sempre la pàgina més antiga.
És senzill d’implementar, però pot portar a un rendiment subòptim en alguns casos (ex: Anomalies de Belady).
Ex: Reemplaç FIFO
Assumeix 3 marcs i la següent seqüència de referències a pàgines: 0 → 7 → 5 → 8 → 10 → 12 → 0 → 10 → 8 → 5 → 9 → 7
Funcionament
| Ref | F1 | F2 | F3 | Fault | Expulsa |
|---|---|---|---|---|---|
| 0 | 0 | – | – | ✓ | – |
| 7 | 0 | 7 | – | ✓ | – |
| 5 | 0 | 7 | 5 | ✓ | – |
| 8 | 8 | 7 | 5 | ✓ | 0 |
| 10 | 8 | 10 | 5 | ✓ | 7 |
| 12 | 8 | 10 | 12 | ✓ | 5 |
| 0 | 0 | 10 | 12 | ✓ | 8 |
| 10 | 0 | 10 | 12 | ✗ | – |
| 8 | 0 | 8 | 12 | ✓ | 10 |
| 5 | 0 | 8 | 5 | ✓ | 12 |
| 9 | 9 | 8 | 5 | ✓ | 0 |
| 7 | 9 | 7 | 5 | ✓ | 8 |
Remplaçament de pàgines - LRU
L’algorisme LRU (Least Recently Used) substitueix la pàgina que no ha estat utilitzada durant el període de temps més llarg.
El funcionament bàsic consisteix a mantenir un registre de l’ordre d’ús de les pàgines i expulsar la que fa més temps que no s’utilitza.
És una aproximació pràctica a Óptim quan les referències presenten localitat temporal.
No es pot implementar de manera eficient sense suport de maquinari (cadenes, timestamps, etc.).
Ex: Reemplaç LRU
Assumeix 3 marcs i la següent seqüència de referències a pàgines: 0 → 7 → 5 → 8 → 10 → 12 → 0 → 10 → 8 → 5 → 9 → 7
Funcionament
| Ref | F1 | F2 | F3 | Fault | Expulsa (LRU) |
|---|---|---|---|---|---|
| 0 | 0 | – | – | ✓ | – |
| 7 | 0 | 7 | – | ✓ | – |
| 5 | 0 | 7 | 5 | ✓ | – |
| 8 | 8 | 7 | 5 | ✓ | 0 |
| 10 | 8 | 10 | 5 | ✓ | 7 |
| 12 | 8 | 10 | 12 | ✓ | 5 |
| 0 | 0 | 10 | 12 | ✓ | 8 |
| 10 | 0 | 10 | 12 | ✗ | – |
| 8 | 0 | 10 | 8 | ✓ | 12 |
| 5 | 5 | 10 | 8 | ✓ | 0 |
| 9 | 5 | 9 | 8 | ✓ | 10 |
| 7 | 5 | 9 | 7 | ✓ | 8 |
Reemplaçament de pàgines - 2ª Oportunitat
La Segona Oportunitat és una millora de FIFO que utilitza el bit de referència (R) per evitar expulsar pàgines que han estat utilitzades recentment.
- FIFO selecciona la pàgina més antiga.
- Segona Oportunitat comprova el bit R:
- R = 0 → la pàgina no ha estat usada recentment → s’expulsa.
- R = 1 → la pàgina ha estat usada →
- S’ajusta R = 0
- La pàgina es mou al final de la cua (rep una segona oportunitat).
- Es continua avançant circularment fins trobar una amb R = 0.
La idea és aproximar el comportament de LRU sense haver d’actualitzar estructures costoses.
Ex: Reemplaç 2ª Oportunitat
Assumeix 3 marcs i 0 → 7 → 5 → 8 → 10 → 12 → 0 → 10 → 8 → 5 → 9 → 7
Funcionament
| Ref | F1 | F2 | F3 | Fault | Víctima |
|---|---|---|---|---|---|
| 0 | →0(1) | – | – | ✓ | – |
| 7 | 0(1) | →7(1) | – | ✓ | – |
| 5 | 0(1) | 7(1) | →5(1) | ✓ | – |
| 8 | →0(0) | 7(0) | 5(0) | ✓ | 0 |
| 10 | 8(1) | →7(0) | 5(0) | ✓ | 7 |
| 12 | 8(1) | 10(1) | →5(0) | ✓ | 5 |
| 0 | →8(0) | 10(0) | 12(0) | ✓ | 8 |
| 10 | 0(1) | →10(1) | 12(0) | ✗ | – |
| 8 | →0(0) | 10(0) | 8(1) | ✓ | 12 |
| 5 | →0(0) | 10(0) | 8(1) | ✓ | 0 |
| 9 | 5(0) | →10(0) | 8(0) | ✓ | 10 |
| 7 | 5(0) | 9(1) | →8(0) | ✓ | 8 |
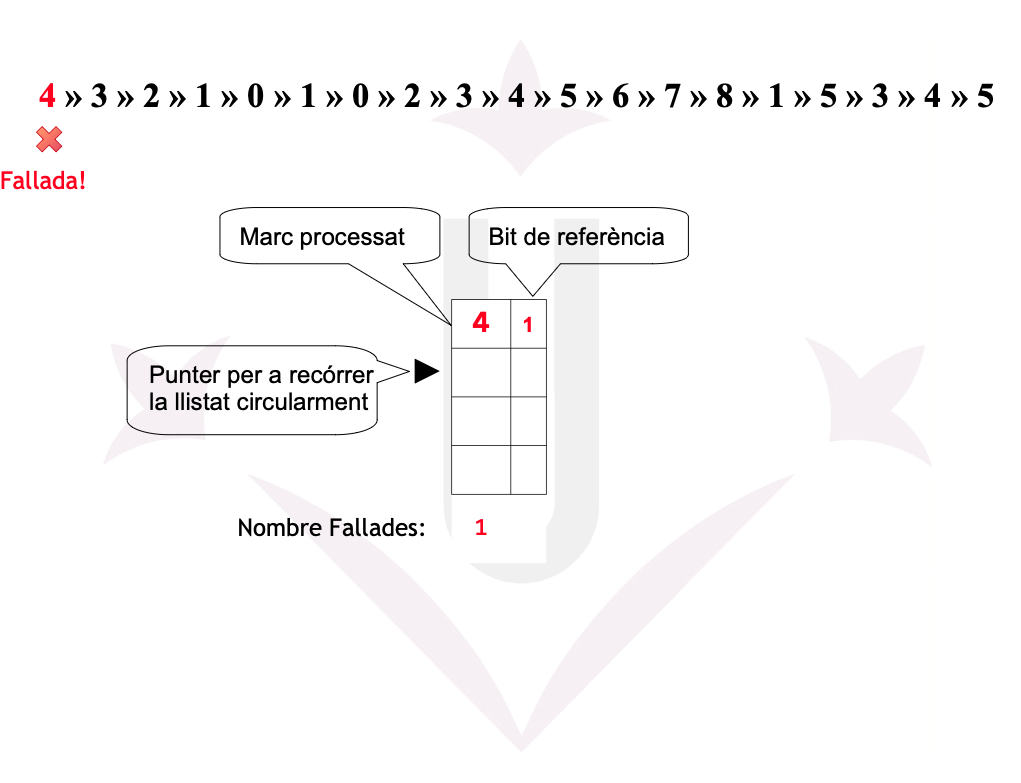
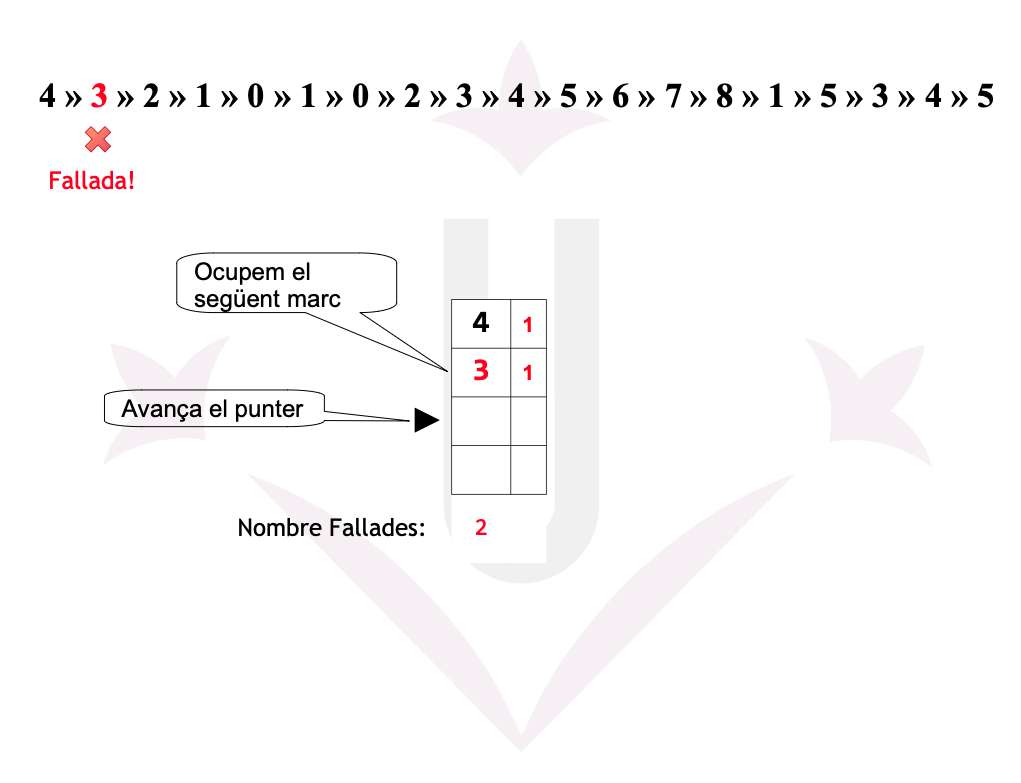
Algorisme de Reemplaçament – Clock Avançat (WSClock)
El WSClock (Working Set Clock) és una millora del 2ª Oportunitat que incorpora:
- Bit de referència (R)
- Bit de modificació (M)
- Temps de l’últim ús (timestamp)
- Conceptes del conjunt de treball (working set)
L’objectiu és expulsar la millor víctima possible: pàgina poc usada, preferiblement no modificada, i fora del seu conjunt de treball.
Funcionament del WSClock
- El punter Clock recorre circularment totes les pàgines.
- Per a cada pàgina, considera 3 criteris:
- \(R = 1\) → s’ha utilitzat recentment → es posa R = 0 i es continua.
- \(R = 0\) i \(M = 0\) → excel·lent candidata per ser expulsada.
- \(R = 0\) i \(M = 1\) → és bona candidata, però cal escriure-la al disc → es marca per write-back i es continua.
- Si cap pàgina compleix les condicions, s’accepta la millor candidata trobada durant el recorregut.
WSClock ≈ 2ª Oportunitat + heurística del conjunt de treball ⇒ Millor rendiment i menys E/S al disc.
Anàlisi del WSClock
- Redueix les escriptures al disc
- Només expulsa pàgines modificades si cal.
- Evita expulsar pàgines del conjunt de treball
- Redueix la hiperpaginació → millor TEA.
- LRU es molt car d’implementar en maquinari; WSClock és barat.
- Algorisme utilitzat en molts sistemes operatius reals com Linux i Windows.
Ex05: Fallades
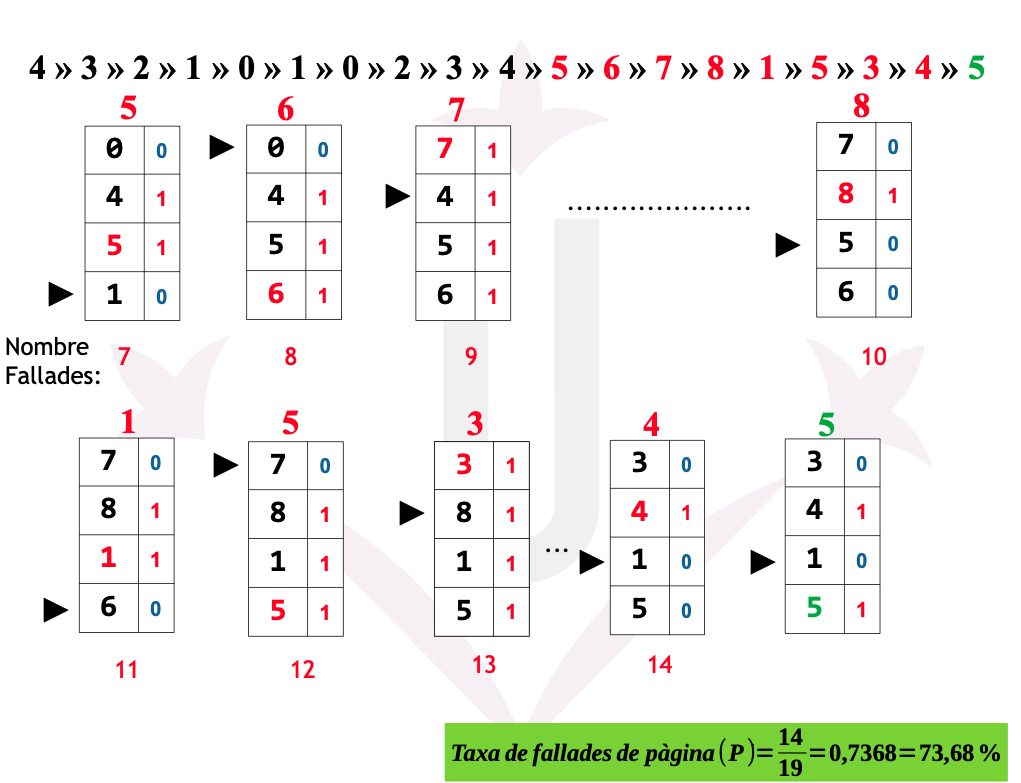
Disposem d’una memòria amb una mida de 4 cel·les. Un programa ha realitzat la seqüència de referències a les 19 pàgines següent:
4 → 3 → 2 → 1 → 0 → 1 → 0 → 2 → 3 → 4 → 5 → 6 → 7 → 8 → 1 → 5 → 3 → 4 → 5
- Quantes fallades de pàgina es produeixen amb l’algorisme FIFO/LRU/2ª Oportunitat i assignació global de cel·les?
- Quina ha estat la tassa de fallades de pàgina?
Ex05: FIFO - Fallades

Ex05: FIFO - Fallades

Ex05: FIFO - Fallades

Ex05: FIFO - Fallades

Ex05: FIFO - Fallades

Ex05: FIFO - Fallades

Ex05: FIFO - Fallades

Ex05: FIFO - Fallades

Ex05: FIFO - Fallades

Ex05: FIFO - Fallades

Ex05: FIFO - Fallades

Ex05: LRU - Fallades
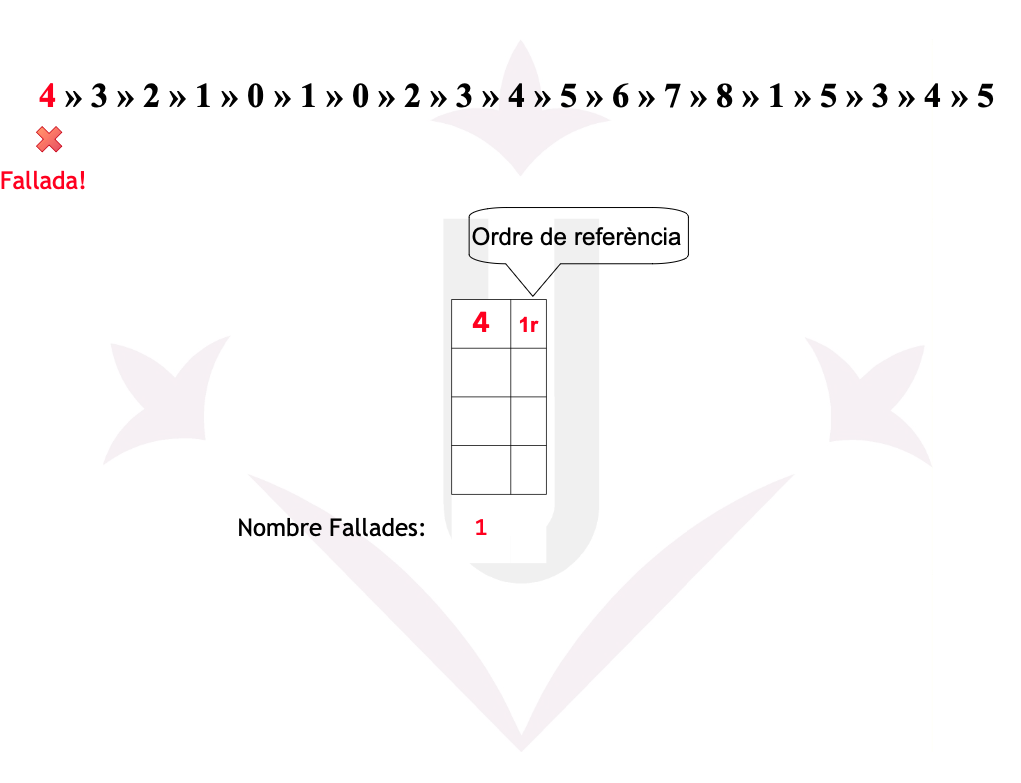
Ex05: LRU - Fallades
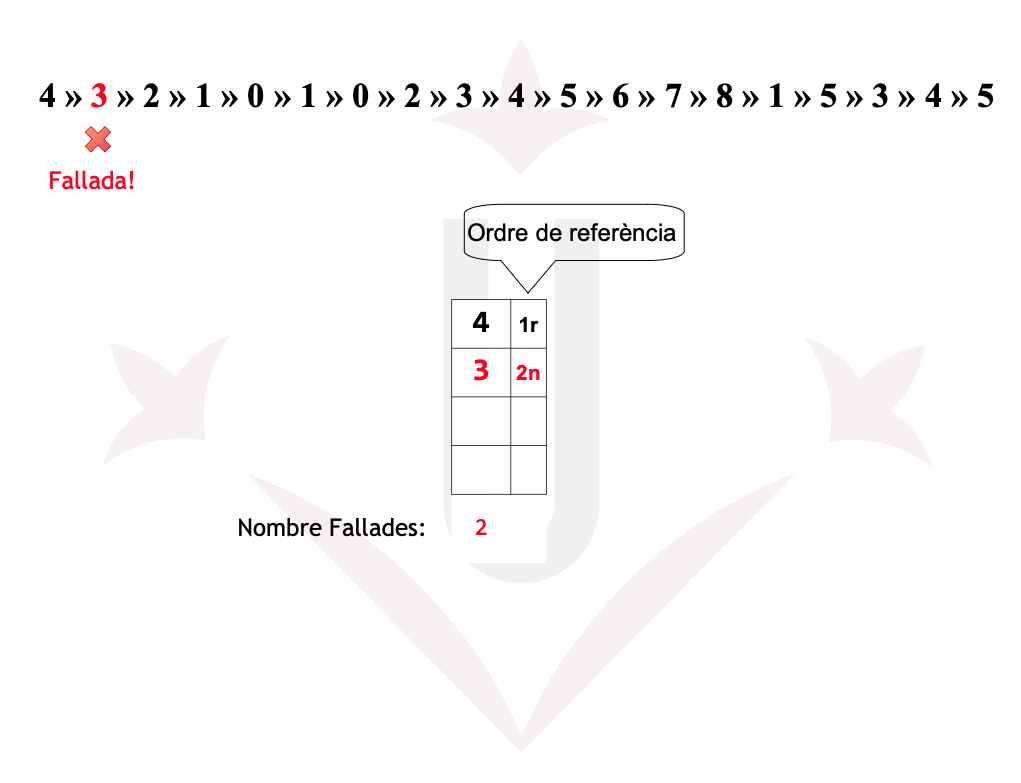
Ex05: LRU - Fallades
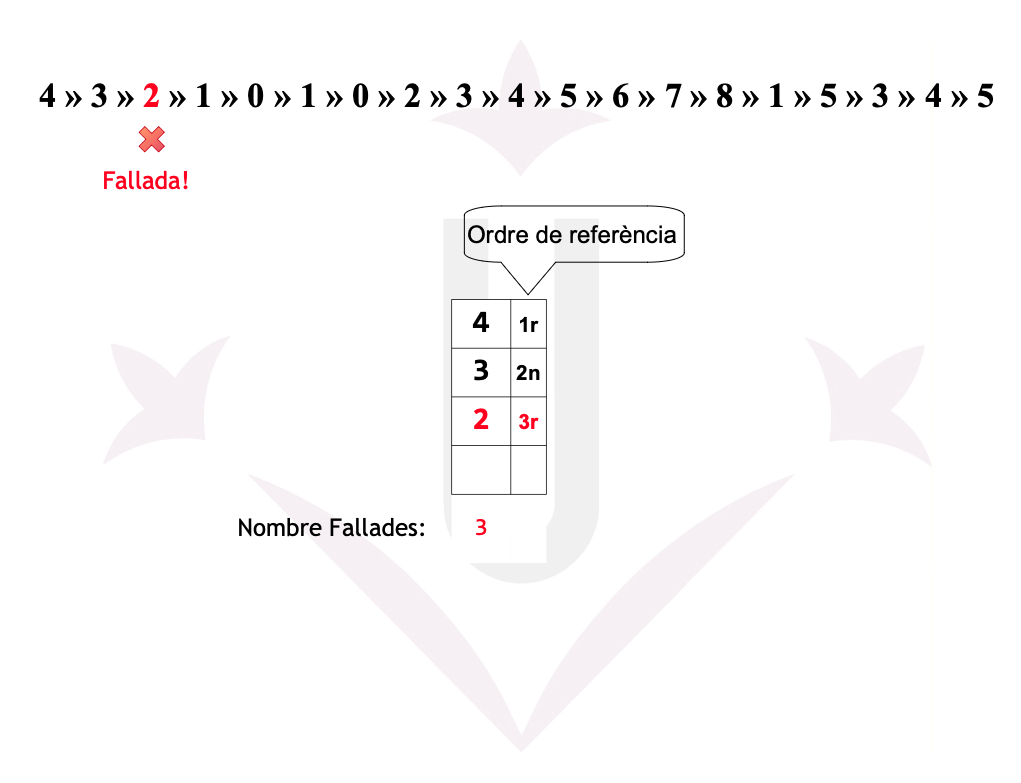
Ex05: LRU - Fallades
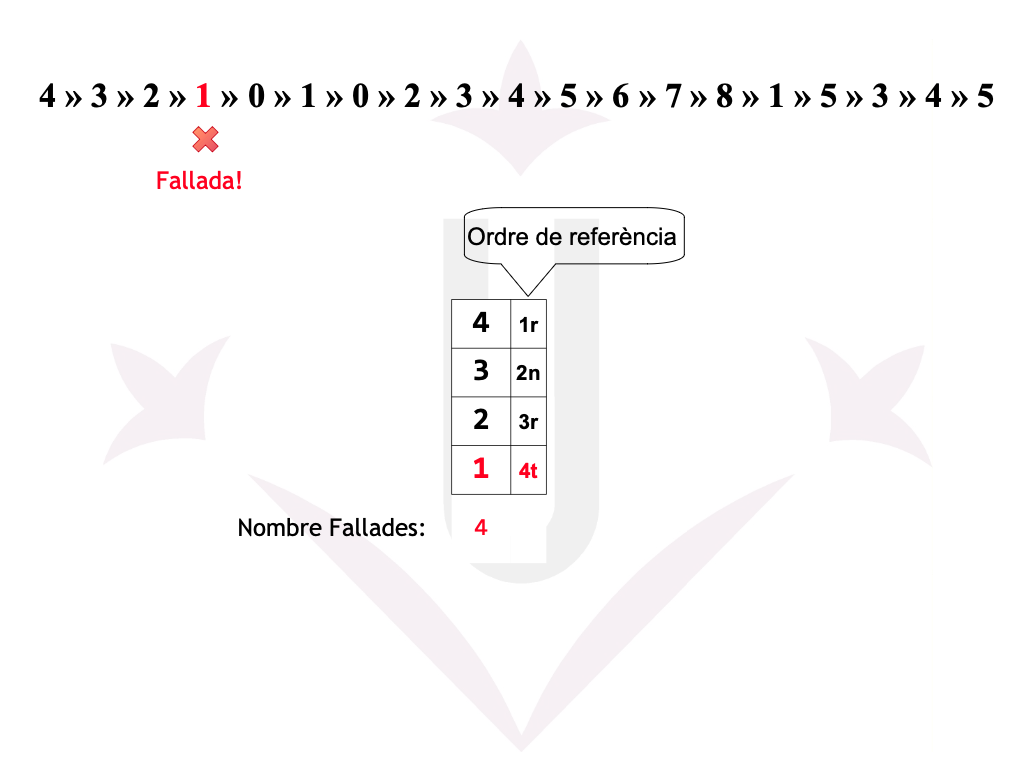
Ex05: LRU - Fallades
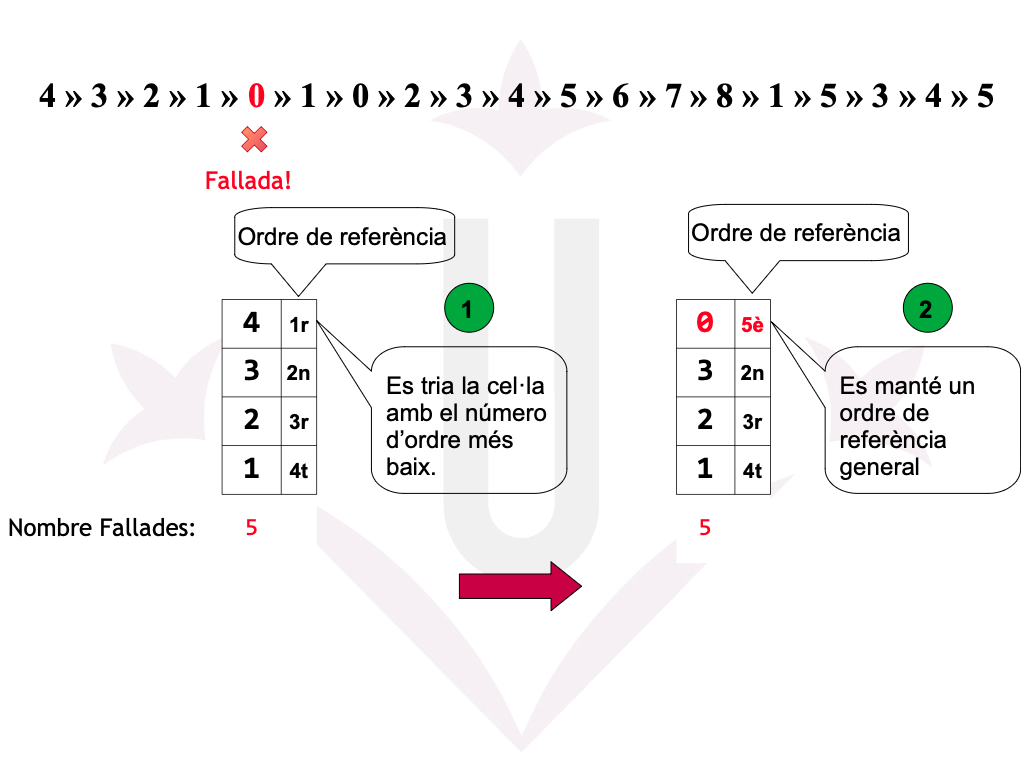
Ex05: LRU - Fallades {.smaller}-
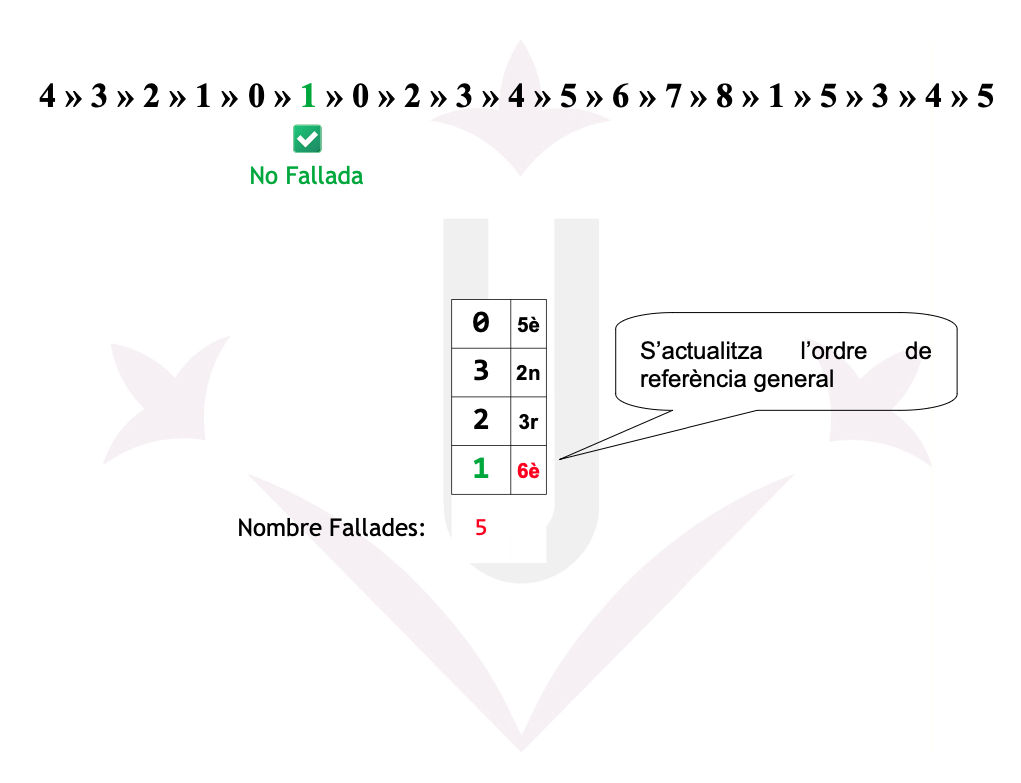
Ex05: LRU - Fallades
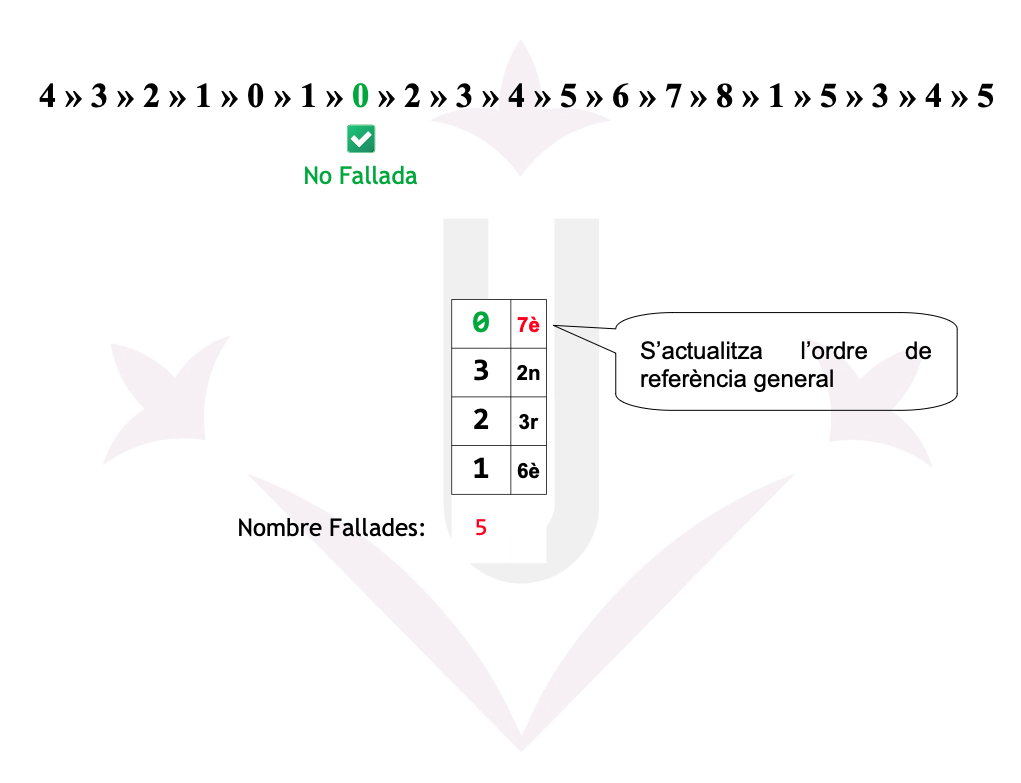
Ex05: LRU - Fallades
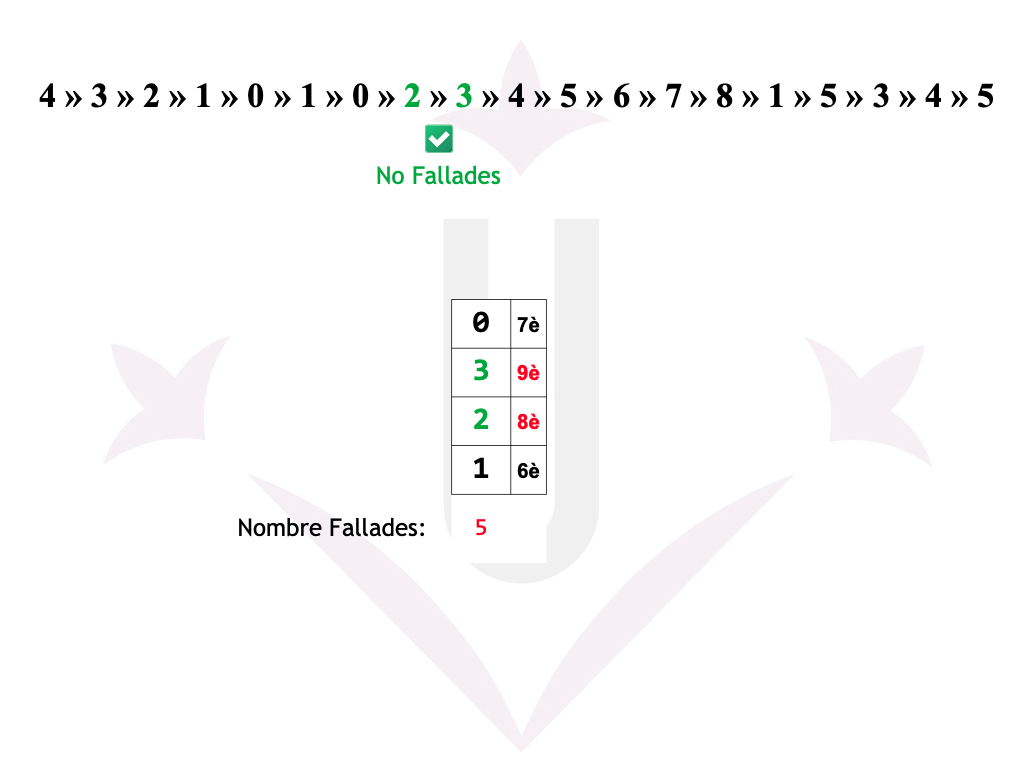
Ex05: LRU - Fallades
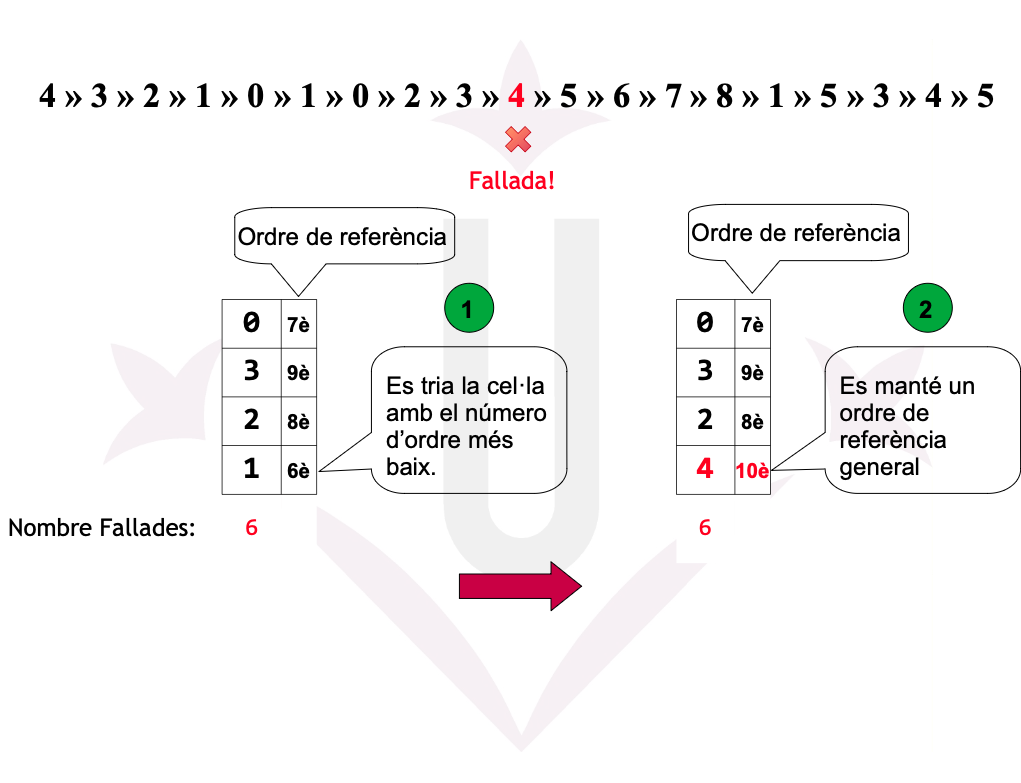
Ex05: LRU - Fallades
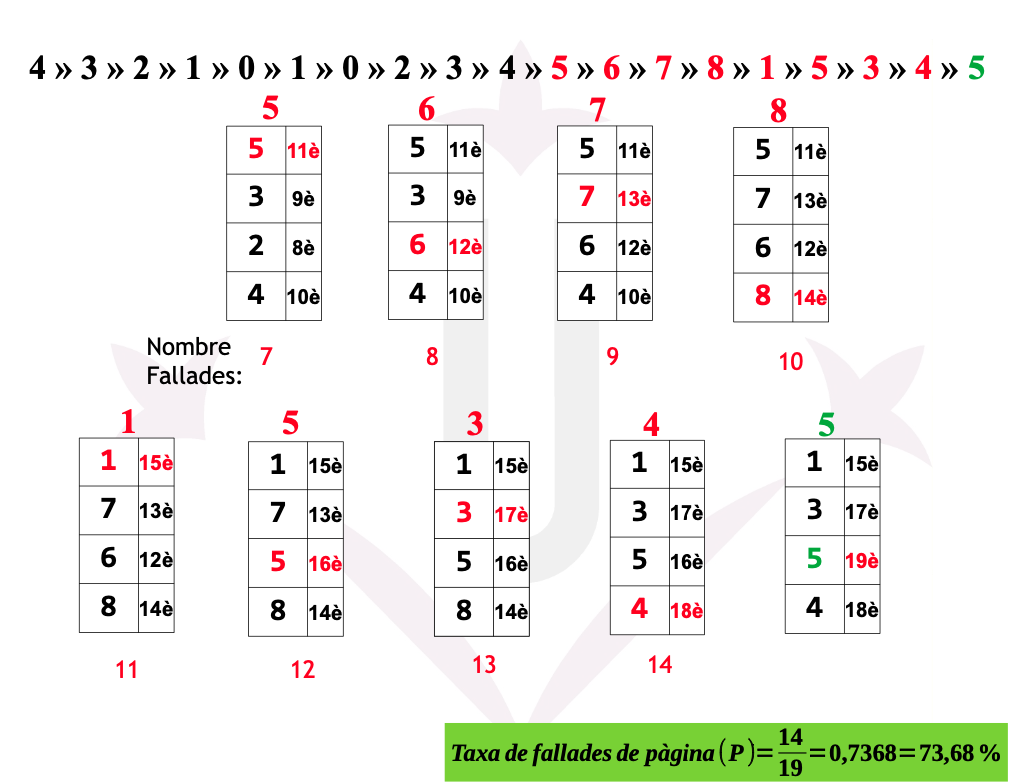
Ex05: 2ª Oportunitat - Fallades
Ex05: 2ª Oportunitat - Fallades
Ex05: 2ª Oportunitat - Fallades
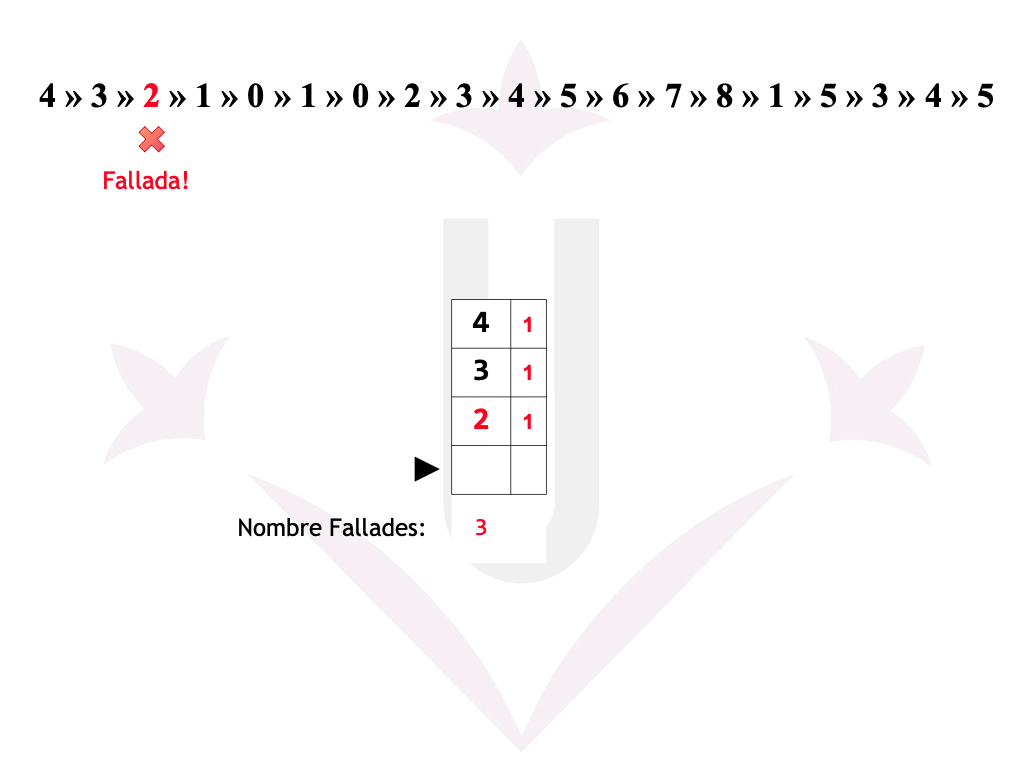
Ex05: 2ª Oportunitat - Fallades
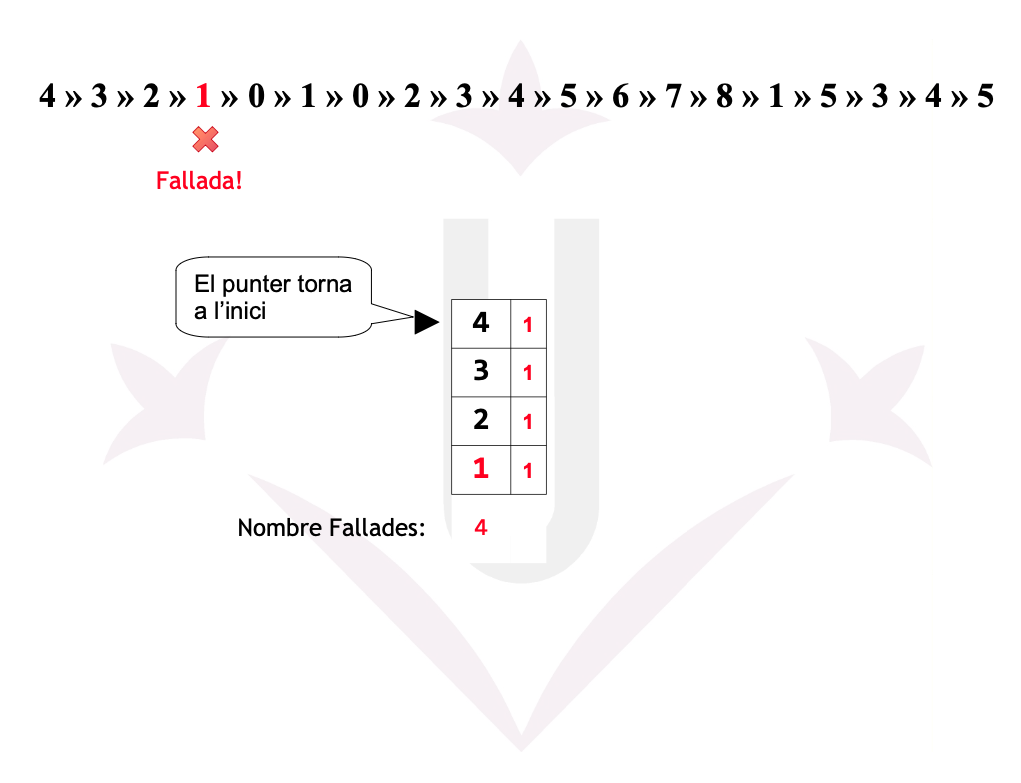
Ex05: 2ª Oportunitat - Fallades
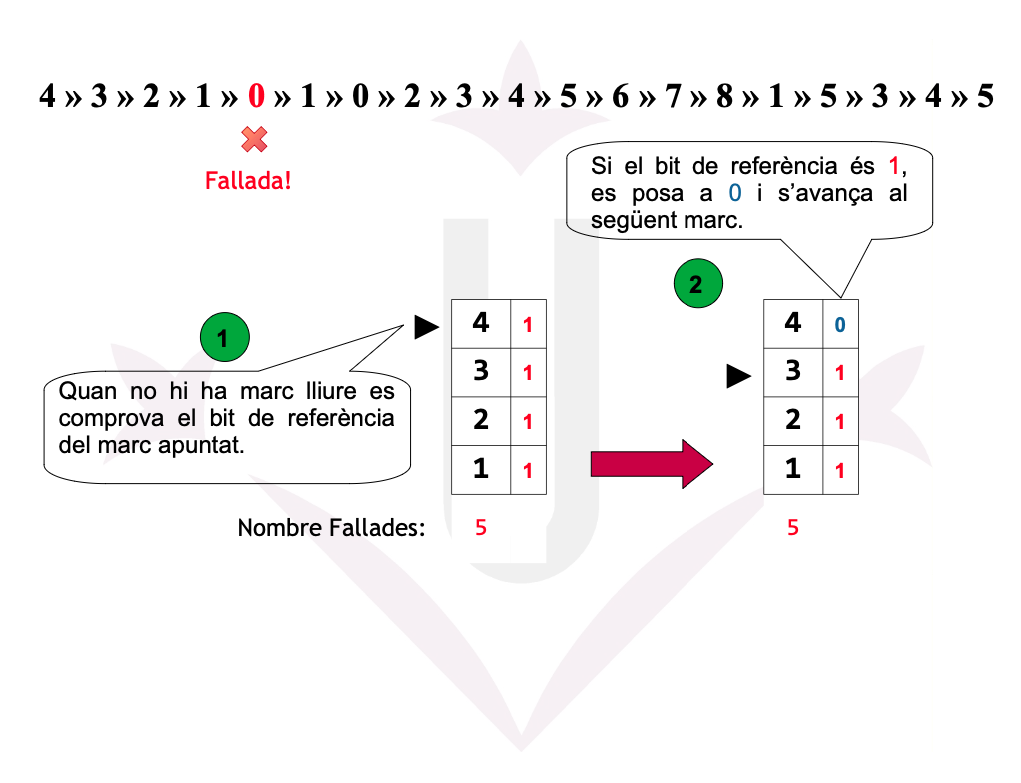
Ex05: 2ª Oportunitat - Fallades
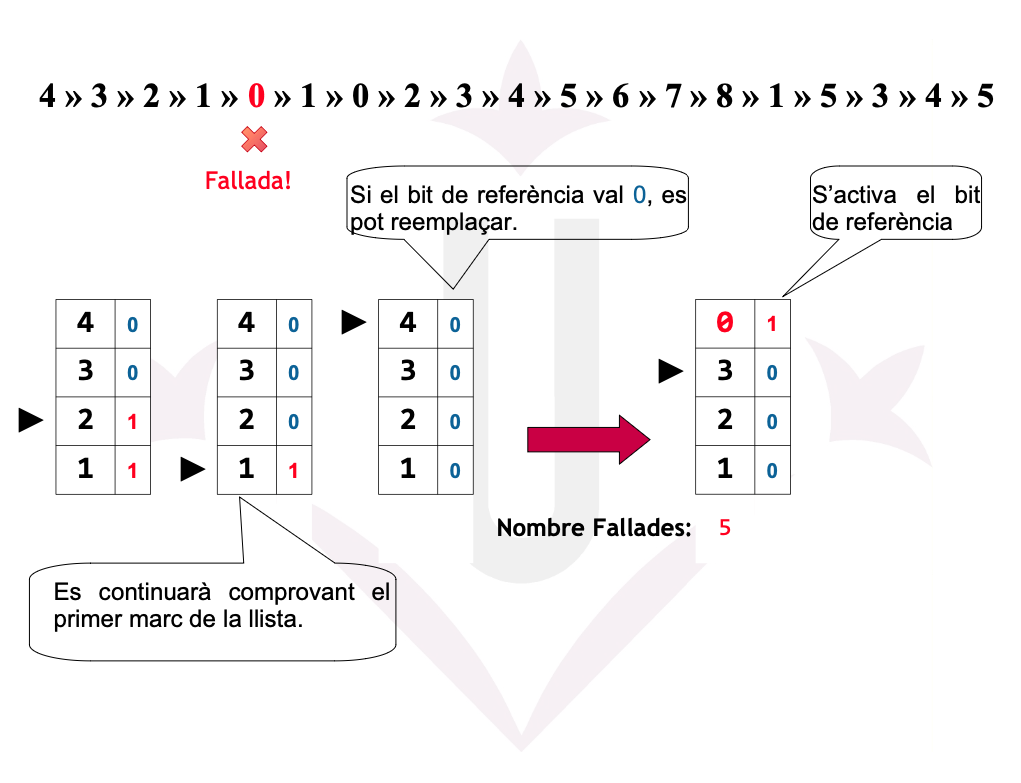
## Ex05: 2ª Oportunitat - Fallades
Ex05: 2ª Oportunitat - Fallades
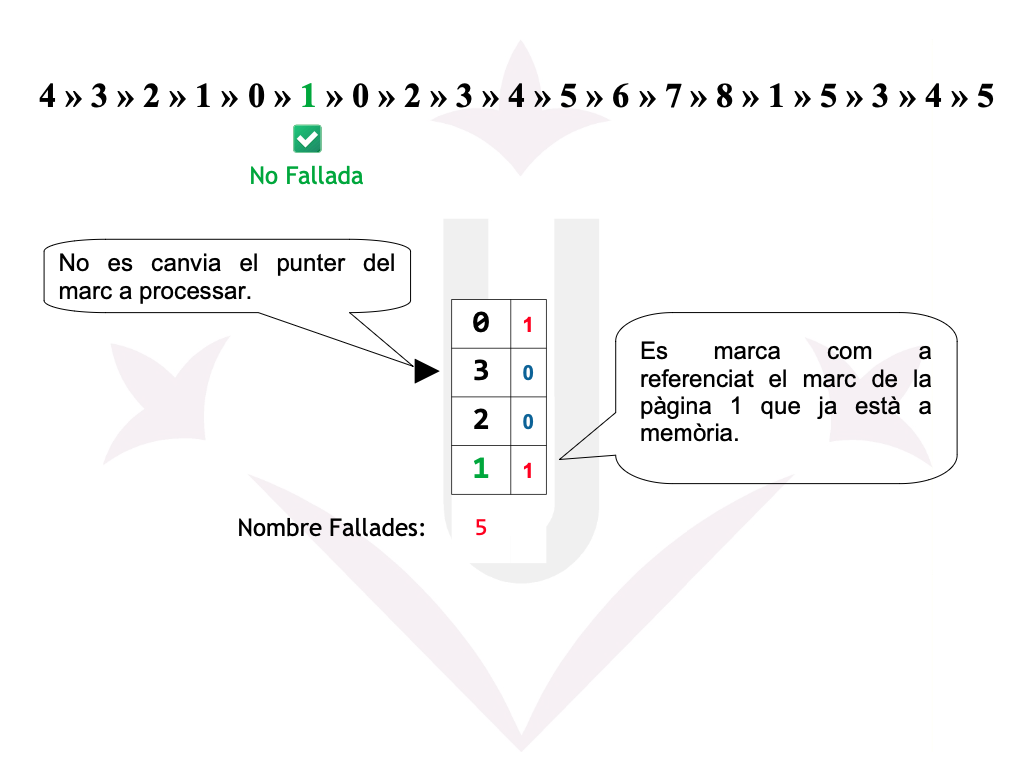
Ex05: 2ª Oportunitat - Fallades
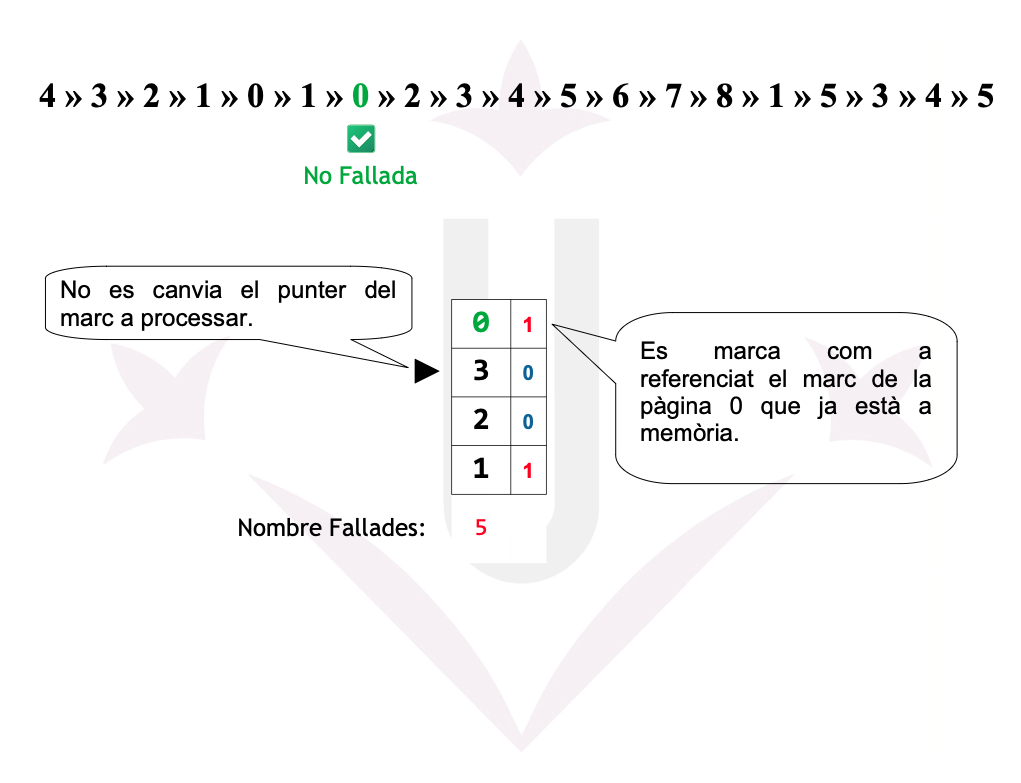
Ex05: 2ª Oportunitat - Fallades
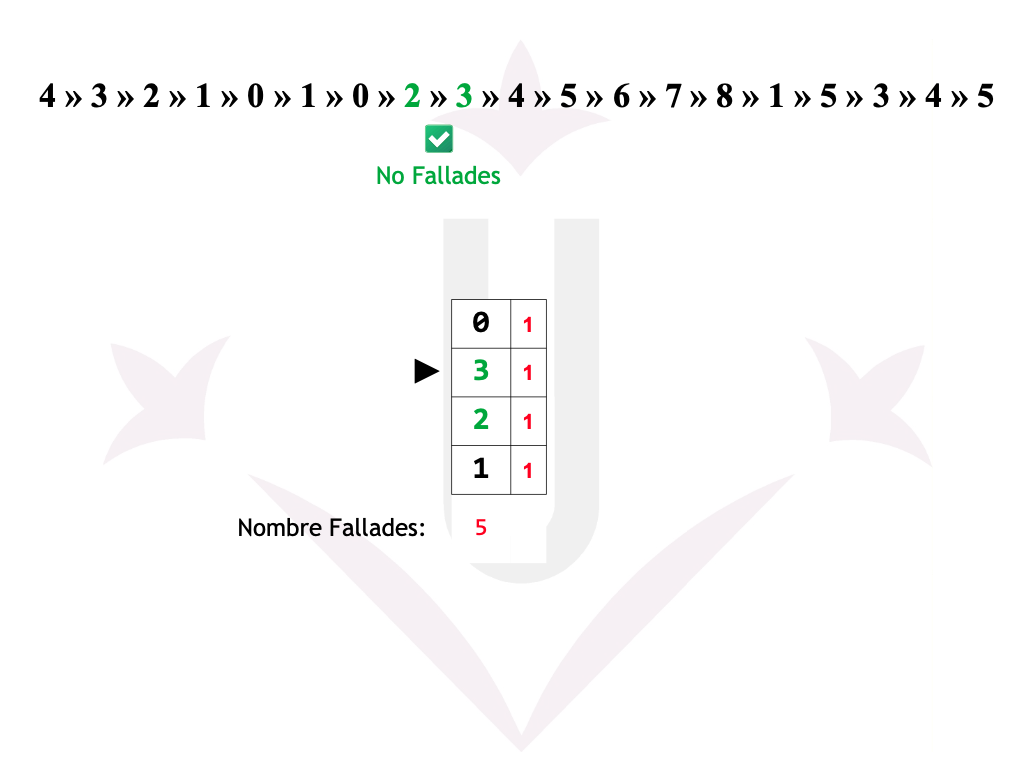
Ex05: 2ª Oportunitat - Fallades
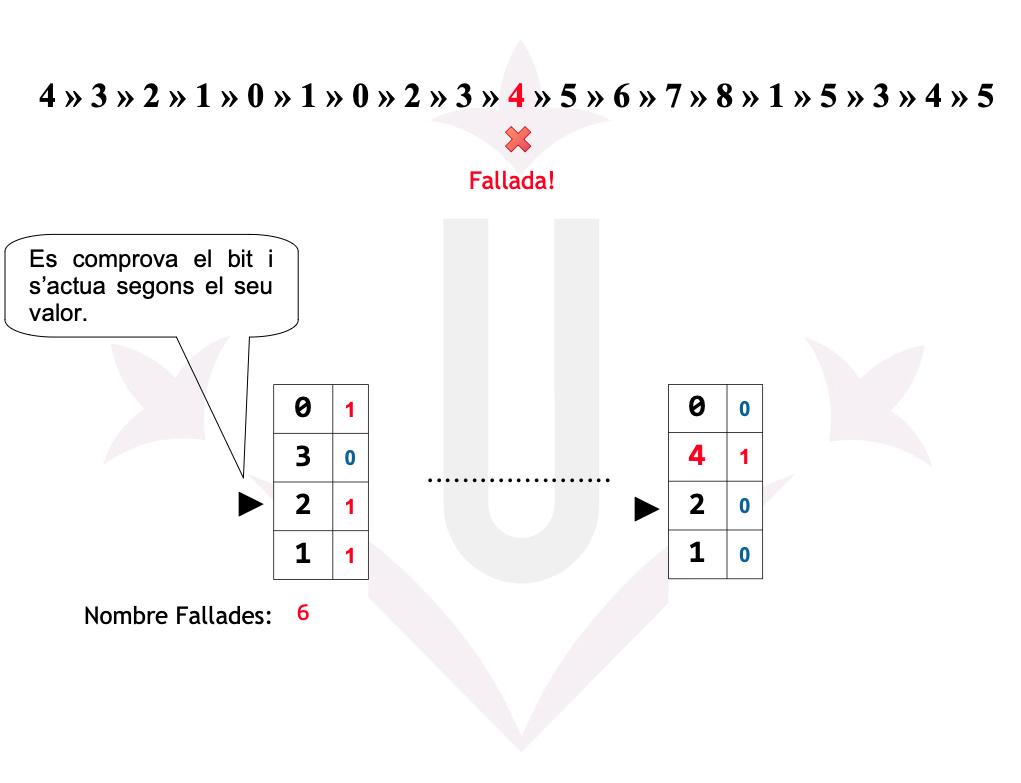
Ex05: 2ª Oportunitat - Fallades
Anòmalies de Belady
Una anomalia de Belady es produeix quan un algorisme de reemplaçament com FIFO té més fallades de pàgina quan augmentem el nombre de marcs.
És contraintuïtiu -> més memòria hauria de significar menys fallades, però amb alguns algorismes això no és cert.
Per exemple, amb la seqüència següent: 1 → 2 → 3 → 4 → 1 → 2 → 5 → 1 → 2 → 3 → 4 → 5 i l’algorisme FIFO:
- Si tenim 3 marcs, es produeixen 9 fallades de pàgina.
- Si tenim 4 marcs, es produeixen 10 fallades de pàgina.
FIFO pot empitjorar quan augmentem els marcs. És l’únic algorisme clàssic on apareix aquesta anomalia.
Ex06: Anòmalies de Belady
1 → 2 → 3 → 4 → 1 → 2 → 5 → 1 → 2 → 3 → 4 → 5
3 marcs
| T | C1 | C2 | C3 | Falla? |
|---|---|---|---|---|
| 1 | 1 | – | – | ✔ |
| 2 | 1 | 2 | – | ✔ |
| 3 | 1 | 2 | 3 | ✔ |
| 4 | 4 | 2 | 3 | ✔ |
| 1 | 4 | 1 | 3 | ✔ |
| 2 | 4 | 1 | 2 | ✔ |
| 5 | 5 | 1 | 2 | ✔ |
| 1 | 5 | 1 | 2 | ✘ |
| 2 | 5 | 1 | 2 | ✘ |
| 3 | 5 | 3 | 2 | ✔ |
| 4 | 5 | 3 | 4 | ✔ |
| 5 | 5 | 3 | 4 | ✘ |
4 marcs
| T | C1 | C2 | C3 | C4 | Falla? |
|---|---|---|---|---|---|
| 1 | 1 | – | – | – | ✔ |
| 2 | 1 | 2 | – | – | ✔ |
| 3 | 1 | 2 | 3 | – | ✔ |
| 4 | 1 | 2 | 3 | 4 | ✔ |
| 1 | 1 | 2 | 3 | 4 | ✘ |
| 2 | 1 | 2 | 3 | 4 | ✘ |
| 5 | 5 | 2 | 3 | 4 | ✔ |
| 1 | 5 | 1 | 3 | 4 | ✔ |
| 2 | 5 | 1 | 2 | 4 | ✔ |
| 3 | 5 | 1 | 2 | 3 | ✔ |
| 4 | 4 | 1 | 2 | 3 | ✔ |
| 5 | 4 | 5 | 2 | 3 | ✔ |
Buffering de pàgines (I)
El buffering de pàgines és una tècnica que intenta reduir el cost de les fallades de pàgina mantenint una reserva de marcs lliures.
Quan es produeix una fallada de pàgina:
- No cal executar immediatament l’algorisme de reemplaçament.
- El SO assigna un marc de la reserva, reduint la latència percebuda pel procés.
S’utilitza un marc lliure, però encara no s’ha alliberat cap pàgina resident.
Buffering de pàgines (II)
Quan el nombre de marcs lliures cau per sota d’un llindar \(\theta\), el SO:
- Activa l’algorisme de reemplaçament.
- Recull pàgines no modificades → van a la free list.
- Recull pàgines modificades → van a la modified list, on es mantenen fins que s’escriuen al disc.
- Una pàgina que es trobi en alguna llista (lliure o modificada) pot ser recuperada ràpidament si es torna a referenciar.
El buffering converteix el reemplaçament immediat en un procés diferit, suavitzant l’impacte de les fallades.
Ex07: Buffering de pàgines
Suposem un sistema amb una Memòria Principal amb 6 marcs i una \(\theta=2\). Utilitzarem l’algorisme FIFO per gestionar el reemplaçament de pàgines.
- Inicialització:
- MP: [ ] [ ] [ ] [ ] [ ] [ ]
- Free list: [F1,F2,F3,F4,F5,F6]
- Modified list: [ ]
- Carreguem P1 i P2:
- MP: [P1] [P2] [ ] [ ] [ ] [ ]
- Free list: [F3,F4,F5,F6]
- Modified list: [ ]
- Cap reempaçament necessari.
Ex07: Buffering de pàgines
- Carreguem P3 i P4:
- MP: [P1] [P2] [P3] [P4] [ ] [ ]
- Free list: [F5,F6]
- Modified list: [ ]
- Encara \(\geq \theta\) (Free list = 2).
- Carreguem P5 i P6:
- MP: [P1] [P2] [P3] [P4] [P5] [P6]
- Free list: [ ]
- Modified list: [ ]
- Ara < \(\theta\) (Free list = 0) → activem reemplaçament.
- Assumirem que cap pàgina està modificada.
Ex07: Buffering de pàgines
- FIFO reemplaçament: P1 → P2 → P3 → P4 → P5 → P6
- Expulsem P1:
- MP: [] [P2] [P3] [P4] [P5] [P6]
- Free list: [F1]
- Modified list: [ ]
- Encara < \(\theta\) → continuem reemplaçant.
- Expulsem P2:
- MP: [] [] [P3] [P4] [P5] [P6]
- Free list: [F1,F2]
- Modified list: [ ]
- Ara \(\geq \theta\) → aturem reemplaçament.
- Expulsem P1:
Ex07: Buffering de pàgines
- Carreguem P7:
- Agafem un marc lliure de la free list (F1):
- MP: [P7] [] [P3] [P4] [P5] [P6]
- Free list: [F2]
- Modified list: [ ]
- Com free list = 1 < \(\theta\) → activem reemplaçament.
- FIFO reemplaçament: Expulsem P3:
- MP: [P7] [] [] [P4] [P5] [P6]
- Free list: [F2,F3]
- Modified list: [ ]
- Ara \(\geq \theta\) → aturem reemplaçament.
Ex07: Buffering de pàgines
- Carreguem P8:
- Agafem un marc lliure de la free list (F2):
- MP: [P7] [P8] [] [P4] [P5] [P6]
- Free list: [F3]
- Modified list: [ ]
- Com free list = 1 < \(\theta\) → activem reemplaçament.
- FIFO reemplaçament: Expulsem P4:
- MP: [P7] [P8] [] [] [P5] [P6]
- Free list: [F3,F4]
- Modified list: [ ]
- Ara \(\geq \theta\) → aturem reemplaçament.
Retenció de pàgines
- No totes les pàgines poden ser expulsades:
- Algunes pàgines del SO no són reemplaçables.
- Certes aplicacions necessiten residència garantida (real-time, dispositius, memòria crítica).
Una aplicació pot demanar que determinades pàgines no surtin mai de la MP:
La retenció garanteix latència baixa i evita fallades crítiques.
Ex08: Calcul del nombre de fallades
- Disposem d’un sistema amb paginació sota demanda.
- Mida de pàgina = 200 paraules
- Assignació local igualitària amb 3 cel·les per procés.
- L’algorisme de reemplaçament és LRU.
- Cada paraula ocupa 1 byte i cada enter ocupa 1 byte.
Assumim que i i j estan en registres i no ocupen memòria. La matriu A està emmagatzemada per files (row-major).
Ex08: Calcul del nombre de fallades
La matriu A té 100x100 = 10.000 enters → ocupa 10.000 paraules.
Mida de pàgina = 200 paraules → \(200\frac{enters}{pàgina}\).
Nombre de pàgines necessàries per a A: \(\frac{10.000 paraules}{200\frac{paraules}{pàgina}} = 50 pàgines\).
Cada fila ocupa 100 bytes. Com que una pàgina conté 200 bytes,cada pàgina conté exactament 2 files completes.
- Pàgina 0 conté A[0][0] a A[1][99]
- La pàgina 1 conté A[2][0] a A[3][99]
- …
El bucle recorregut fila a fila provoca que cada 2 files s’accedeixi a una nova pàgina.
Ex08: Calcul del nombre de fallades
Resultat
Per tant, hi haurà una fallada de pàgina cada 2 files. Amb 100 files, hi haurà 50 fallades de pàgina en total sobre l’accés a la matriu A.
Nota
Si vols comptar també la possible fallada inicial per carregar codi/taules del procés a MP, s’hi pot sumar 1 → 51 en total.
Ex08: Comportament amb 3 marcs i LRU
- Els 3 marcs assignats al procés no redueixen aquest nombre de misses en aquest patró seqüencial: cada pàgina s’accedeix una sola vegada i no hi ha reuse, de manera que LRU (amb 3 marcs) carregarà cada pàgina exactament un cop.
- Durant l’execució, després d’omplir els 3 marcs, cada nova pàgina expulsarà la menys recentment utilitzada (equivalent, en aquest cas seqüencial, a expulsar la més antiga entre les resident).
Ex09: Calcul del nombre de fallades
Repeteix els càlculs anteriors però assumint que ara la matriu A està emmagatzemada per columnes (column-major).
Ex09: Calcul del nombre de fallades
En column-major, la memòria s’organitza per columnes: les posicions consecutives corresponen a A[0][c], A[1][c], A[2][c], ….
Cada columna té 100 enters; cada pàgina conté 200 enters → cada pàgina conté 2 columnes:
- pàgina 0 → columnes 0 i 1 de totes les files A[0] A[1]
- pàgina 1 → columnes 2 i 3 de totes les files A[2] A[3]
- …
- pàgina 49 → columnes 98 i 99 de totes les files A[98] A[99]
Warning
El patró d’accés generat pel doble bucle (primer i, després j) visita les cel·les en ordre: A[0][0], A[0][1], A[0][2], …, A[0][99], A[1][0], A[1][1], …, A[99][99] Per a column-major això significa: per una fila fixa i anem saltant entre columnes i, per tant, entre moltes pàgines diferents.
Ex09: Calcul del nombre de fallades
Per una fila i fixa la seqüència de pàgines és: p(0), p(1), p(2), …, p(49)
Cada pàgina p(k) s’accedeix dues vegades consecutives per cada fila i (per j=0 i j=1)
1a utilització de p(k) → fallada (ja que no està a MP)
2a utilització de p(k) → hit (ja que acaba de ser carregada)
La proper reutilització de p(k) es produeix només a la fila següent (i+1), després d’haver visitat totes les altres pàgines entre mig.
La reuse distance (nombre de pàgines úniques entre dues utilitzacions de la mateixa pàgina) és 49.
Com que els marcs assignats = 3 i 49 > 3, LRU no pot retenir p(k) fins al seu pròxim ús → la pàgina serà expulsada abans de la següent reutilització.
Ex09: Calcul del nombre de fallades
- Cada fila \(i\) provoca 50 fallades de pàgina (una per cada pàgina p(0) a p(49)).
- Per cada pàgina p(k), en una fila \(i\) s’accedeix dues vegades (j=0 i j=1):
- 1a accés → fallada
- 2a accés → hit (immediatament després)
- Per fila, hi ha 50 misses (1 per cada pàgina).
- Amb 100 files, el total de fallades és: \(100 \text{ files} \times 50 \text{ fallades/fila} = 5000 \text{ fallades}\).
Conclusió
En column-major, amb 3 marcs i LRU, es produeixen 5000 fallades de pàgina en total, o 5001 si comptem la possible fallada inicial per carregar codi/taules del procés a MP.

Unitat 6 · Sistemes Operatius (SO) 🏠